






I. Tâche, Thread et ThreadPool▲
Il existe plusieurs raisons pour vouloir utiliser du multi-tâche au sein de nos programmes.
On peut vouloir améliorer l'expérience utilisateur en rendant les interfaces plus réactives. Par exemple, en déportant le téléchargement d'un fichier dans un autre thread, afin de ne pas bloquer le thread gérant l'affichage.
On peut vouloir améliorer les performances d'un algorithme en tirant parti des architectures multicœurs des processeurs actuels. En séparant un ensemble de données en plusieurs sous-ensembles, et en traitant chacun de ces ensembles sur un processeur différent, il est possible de traiter plus rapidement toutes ces données.
Quelles que soient les raisons qui nous poussent à vouloir utiliser le parallélisme, il est important de savoir comment on peut le faire.
Dans ce tutoriel, je vais aborder une approche possible en C#, via l'utilisation du pool de threads, en précisant ses avantages et ses inconvénients, notamment vis-à-vis de l'approche classique qu'est la création de threads.
Ce tutoriel est le premier d'une série de quatre tutoriels. Les suivants traiteront :
- des fabriques de tâches, des jetons d'annulation et du chaînage de tâches ;
- de l'usage de async/await ;
- des tâches sporadiques et périodiques.
II. Définition▲
Avant d'aller plus loin, il est nécessaire de faire un descriptif de la terminologie qui sera employée dans le reste de ce tutoriel.
II-A. Processus (Process) : environnement d'exécution d'une application▲
Un processus est une collection de ressources associées à une instance d'une application. Chaque processus dispose de ses propres ressources qui ne peuvent être accédées depuis un autre processus. Cela permet une isolation des applications et évite qu'une instance d'une application ne corrompe une autre instance (par exemple en cas de plantage).
Les ressources en question sont principalement un espace d'adressage qui contiendra à la fois le code et les données de l'application.
II-B. Thread▲
Un thread est un concept permettant de virtualiser le processeur, et donc d'exécuter des instructions. Son objectif est de permettre de partager la ressource qu'est le processeur entre différentes applications. Chaque processus, lorsqu'il est créé, est associé à un thread exécutant le code lié à ce processus et agissant sur les données de ce même processus.
Ainsi, si une application entre dans une boucle infinie, seule cette application sera « gelée », et non tout le système entier.
Un processus a au minimum un thread. Mais ce n'est qu'un minimum et un processus peut avoir autant de threads que nécessaire (en fonction des limites du système, bien entendu).
Je me suis posé la question de savoir s'il fallait ou non traduire le terme « thread » par celui de « tâche » ou de « fil d'exécution » dans ce tutoriel. Pour des raisons de clarté, j'ai préféré ne pas le faire. En effet, le terme « tâche » en français sera utilisé pour désigner un autre concept.
II-C. Tâche▲
Une tâche est une action à exécuter (envoyer un e-mail, télécharger un fichier, effectuer un long calcul, etc.).
Elle peut être :
- ponctuelle (elle ne sera exécutée qu'une seule fois) ;
- sporadique (elle sera exécutée plusieurs fois, en fonction d'un événement particulier) ;
- ou périodique (elle sera exécutée à intervalle régulier).
Dans le cadre de ce tutoriel, nous considérerons uniquement les tâches ponctuelles. Les tâches sporadiques et périodiques seront traitées dans le quatrième et dernier tutoriel de cette série.
II-D. Pool de Threads▲
Un pool de threads est un ensemble de threads utilisables pour exécuter des tâches en fonction des besoins.
En .Net, chaque processus est affecté d'un pool de threads qui est accessible via la classe System.Threading.ThreadPool.
II-E. Notion de Task▲
Le terme « task » désignera une instance de la classe System.Threading.Tasks.Task (cf. fin du tutoriel).
III. Pourquoi utiliser le Pool de Threads ?▲
III-A. Quand l'utiliser ?▲
La création d'un nouveau thread est un acte coûteux en ressources, aussi bien d'un point de vue processeur (CPU) que d'un point de vue mémoire. Aussi, dans le cas où un programme nécessite d'exécuter de nombreuses tâches, la création et la suppression d'un thread pour chacune d'entre elles pénaliseraient grandement les performances de l'application. De ce fait, il serait intéressant de pouvoir mutualiser la création des threads afin qu'un thread ayant fini l'exécution d'une tâche soit disponible pour l'exécution d'une tâche future. Et c'est justement là qu'intervient le pool de threads.
III-A-1. Avantages▲
L'objectif du pool de threads est de mettre en commun les threads afin d'éviter des créations ou suppressions de threads intempestives, et ainsi permettre leur réutilisation.
Ainsi, lorsqu'une tâche aura besoin d'être exécutée, il sera plus judicieux en termes de ressources de vérifier si le pool de threads contient un thread disponible. Si oui, il sera retiré du pool le temps d'exécuter la tâche, puis sera remis dans le pool une fois la tâche accomplie.
S'il n'y a pas de thread disponible, un nouveau thread pourra être créé, et à la fin de la tâche, le thread viendra à son tour alimenter le pool de threads.
Si le pool de threads contient déjà un certain nombre de threads, alors la tâche sera simplement mise en attente jusqu'à ce qu'un thread soit à nouveau disponible.
III-A-2. Limitation▲
Attention, il ne faut pas croire pour autant que l'usage du pool de threads n'a que des avantages. Il y a des situations où l'usage de thread « classique » sera nécessaire.
En effet, il n'est pas possible d'agir sur les tâches (mettre en pause ou l'arrêter). Ces opérations nécessitent la création d'un thread.
De plus, il est également impossible de gérer finement l'ordonnancement des threads appartenant à un pool (impossibilité de définir des priorités par exemple). Mais cela reste un cas relativement particulier et très souvent, l'usage du pool de threads sera à privilégier.
III-B. Benchmark▲
J'ai réalisé un mini-benchmark afin de comparer les performances en termes d'usage CPU des deux solutions, afin de se rendre compte du coût relativement élevé de la création des threads.
Ce benchmark est fait pour mettre en évidence le coût lié à la création des threads. Il n'a pas été écrit pour évaluer précisément ce surcoût. Le code du benchmark est disponible avec ce tutoriel (projet « Benchmark »).
|
Mode\Approche |
Thread |
ThreadPool |
|---|---|---|
|
Debug (avec débogueur) |
54594 |
62 |
|
Debug (sans débogueur) |
1534 |
12 |
|
Release |
1496 |
18 |
Les résultats correspondent au temps mis pour l'exécution (en ms) via les différentes approches. On constate qu'il y a aisément un facteur 100 entre l'utilisation du pool de threads et la création des threads, voire 1000 en présence d'un débogueur !
J'ai également comparé la consommation en mémoire de mon programme de test. Voici les résultats :
|
Mode\Approche |
Rien |
Thread |
ThreadPool |
|---|---|---|---|
|
Debug/Profilage |
7,4 Mo |
33,7 Mo |
8,4 Mo |
La colonne « rien » reflète la consommation de base du programme de test, rien que par son exécution. Si on la retranche des autres colonnes, cela permet d'avoir une estimation de la consommation mémoire des différentes approches. Ici encore, on constate que l'utilisation du pool de threads demande moins de mémoire que la création de thread spécifique (un bon facteur 10 dans notre cas).
Voilà, j'espère que ce mini-benchmark vous aura convaincu que l'utilisation du pool de threads est moins gourmande en ressources que sa grande sœur. Voyons donc maintenant, comment l'utiliser !
IV. Usage du pool de threads▲
IV-A. Hello World▲
L'utilisation du pool de threads se fait aisément. Deux composantes sont nécessaires :
- avoir une méthode contenant le code de la tâche à effectuer. Cette méthode doit avoir la signature suivante :
voidNomTache(objecto); - appeler une des surcharges de la méthode ThreadPool.QueueUserWorkItem.
Et c'est tout ! Et pour vous montrer la simplicité de la mise en œuvre, voici un classique « Hello World » :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
namespace HelloWorld
{
class Program
{
static void Main(string[] args)
{
ThreadPool.QueueUserWorkItem(HelloWorld);
Console.WriteLine("Fin du main");
Console.ReadLine();
}
private static void HelloWorld(object data)
{
Console.WriteLine("Hello World depuis une tâche");
}
}
}
Vous pouvez retrouver cet exemple dans le code accompagnant ce tutoriel. Il s'agit du projet « HelloWorld ».
À l'exécution de ce code, vous devriez avoir une sortie ressemblant à celle-ci :
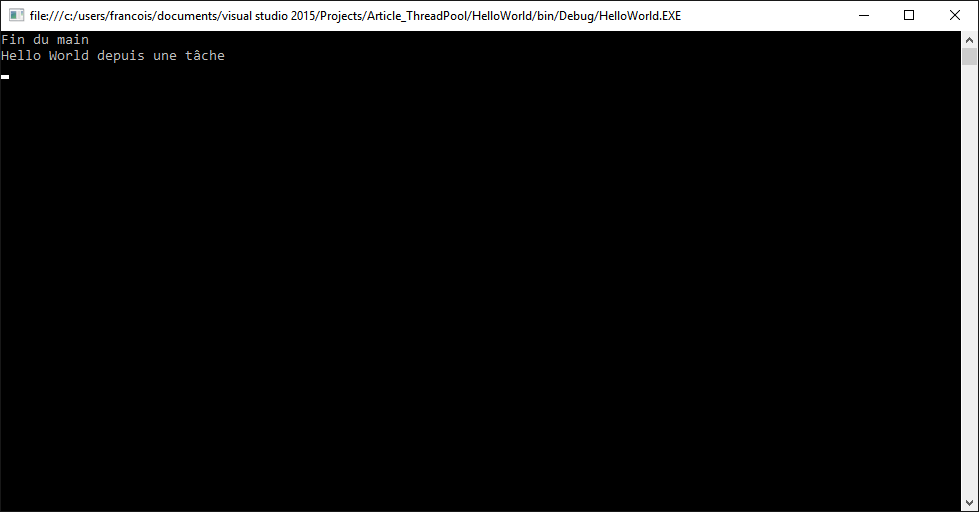
Les deux lignes peuvent être inversées. C'est la « magie » du parallélisme. Il n'est pas possible de savoir à l'avance dans quel ordre les tâches seront exécutées. Nous voyons ici qu'il y a bien eu la création d'une tâche, dans la mesure où la ligne « Fin du main » est bien avant la ligne « Hello World ».
IV-B. Gestion des exceptions▲
Lorsqu'une exception est levée par une tâche en cours d'exécution sur un thread du pool de threads, que se passe-t-il si elle n'est pas gérée ?
Si une exception survient lors de l'exécution d'une tâche au sein d'un thread, et que cette exception n'est pas gérée par le thread, il n'est alors pas possible de propager cette exception dans un autre thread. Le programme est alors arrêté. Oui, le programme tout entier, pas uniquement le thread et la tâche en cours d'exécution !
La première question qu'on peut se poser, c'est pourquoi mettre fin au programme entier alors qu'il aurait été possible de mettre fin uniquement à la tâche. La réponse est relativement simple : pour éviter de maintenir un programme qui soit dans un état incohérent. Imaginez par exemple que la tâche ait acquis une ressource (un mutex par exemple) et qu'une exception survienne. La ressource ne sera alors jamais libérée, laissant le programme entier dans un état indéterminé.
On aurait pu également imaginer que l'exception soit par défaut propagée au thread ayant lancé la tâche fautive. Mais là encore, ce n'est pas possible. Le thread ayant lancé la tâche fautive peut très bien être terminé. Et même si le thread n'est pas terminé, il n'est pas possible de savoir où mettre un bloc try/catch pour gérer l'exception, car concurrence oblige, le thread aura aussi tendance à continuer d'exécuter la tâche qui lui est associée de son côté.
Bref, afin de garantir l'intégrité du programme, la seule solution viable est d'y mettre fin.
C'est pourquoi il est indispensable que le code d'une tâche soit encadré par un bloc try/catch afin d'éviter que cette situation ne se produise, comme le montre l'exemple ci-dessous :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
private static void HelloWorld(object data)
{
try
{
throw new NotImplementedException("Aïe, j'ai oublié d'écrire ma tâche !");
}
catch
{
// Éventuellement, mettre un traitement qui permette de tracer l'exception,
// ou de notifier le programme qu'un problème est survenu.
}
}
Il est très important de prendre en considération les exceptions à la vue des conséquences qu'elles peuvent avoir sur le programme tout entier.
Pour un client lourd, le programme plante, l'utilisateur doit redémarrer le programme. Outre les conséquences désagréables pour l'utilisateur (un programme qui plante n'est jamais agréable), cela peut conduire à des corruptions de données (par exemple, si le programme était en train d'écrire dans un fichier lorsqu'une exception non gérée s'est produite dans l'une de ses tâches).
Mais imaginez sur un serveur (une application ASP.NET ou MVC par exemple). Là, les conséquences sont plus désastreuses dans la mesure où le programme plantant, le serveur est obligé de le relancer. Tous les utilisateurs connectés peuvent alors souffrir des conséquences de cette exception non gérée (de la simple déconnexion à la perte des opérations en cours en passant également par la possible corruption de données).
V. Utiliser un Task▲
V-A. Présentation▲
Nous l'avons vu, l'utilisation du pool de threads souffre de plusieurs défauts, notamment :
- il n'est pas possible d'avoir une valeur de retour ;
- il n'est pas possible de gérer les exceptions en les laissant remonter ;
- il n'est pas possible d'agir sur une tâche (par exemple, l'annuler).
Bien évidemment, il est possible de faire tout cela. Mais comme ce n'est pas prévu à la base, il faut le réaliser soi-même, augmentant donc la taille et la complexité du code à écrire.
Aussi, Microsoft, dans sa grande sagesse, a introduit un nouveau concept avec la version 4 du framework .Net : celle de Task.
Avec cette notion, il va être possible de faire tout cela, et simplement. De plus, à partir du framework 4.5, l'intégration avec le langage C# est poussée encore plus en avant avec l'introduction de deux nouveaux mots-clés : async et await (ce point sera abordé dans le troisième tutoriel de la série dédiée au pool de threads).
La notion de Task repose en interne sur le pool de threads. On garde donc les mêmes avantages quant à la légèreté de cette solution (comparativement à la création de threads bien entendu), tout en levant certaines de ses limitations.
V-B. Lancer une tâche▲
Plutôt que de faire une longue explication, voici une courte démonstration :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
using System;
using System.Threading.Tasks;
namespace ExempleTask
{
class Program
{
static void Main(string[] args)
{
Task task = Task.Run(() => { HelloWorld(); });
Console.WriteLine("Statut du task : {0}", task.Status);
Console.WriteLine("Fin du main");
task.Wait();
Console.WriteLine("Statut du task : {0}", task.Status);
Console.ReadLine();
}
private static void HelloWorld()
{
Console.WriteLine("Hello world depuis un Task");
}
}
}
Cet exemple est disponible dans le projet « ExempleTask ».
Dans cet exemple, on voit qu'il est possible d'aller un peu plus loin que précédemment. On lance une tâche via un appel à Task.Run. Cette méthode retourne un objet de type Task permettant d'interagir ensuite avec notre tâche.
Via la variable « task », il est possible notamment :
- d'observer le statut de la tâche (en cours d'exécution, complétée, etc.) ;
- d'attendre que la tâche se termine.
Cela ouvre déjà de plus grandes perspectives !
V-C. Lancer une tâche avec résultats▲
Il est également possible de lancer une tâche devant renvoyer un résultat. La démarche est très similaire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
using System;
using System.Threading.Tasks;
namespace ExempleTaskWithReturn
{
class Program
{
static void Main(string[] args)
{
Task<string> task = Task.Run(new Func<string>(HelloWorld));
Console.WriteLine("Statut du task : {0}", task.Status);
Console.WriteLine("Fin du main");
Console.WriteLine("Statut du task : {0}", task.Status);
Console.WriteLine(task.Result);
Console.ReadLine();
}
private static string HelloWorld()
{
return "Une chaîne d'autre Task...";
}
}
}
Cette fois-ci, au lieu de récupérer un objet de type Task, on récupère un objet de type Task<string>.
L'utilisation est très similaire à un objet de type Task puisque Task<T> hérite de Task. Mais cette version générique dispose d'une propriété supplémentaire : Result.
Cette propriété permet d'accéder au résultat de la tâche. Et si la tâche n'a pas terminé son exécution au moment de l'accès à cette propriété, alors le thread courant se met en attente jusqu'à ce que la tâche ait fini son exécution.
Si la tâche n'a pas commencé son exécution, alors la tâche est retirée du pool de threads pour être exécutée directement sur le thread en attente de son exécution. Cela évite un changement de contexte.
V-D. Gérer les exceptions▲
Au début du tutoriel, j'ai longuement abordé le sujet des exceptions. Le concept de Task vient ici chambouler un petit peu tout ce qui a été dit plus tôt, et il est donc nécessaire d'y revenir dans ce contexte bien particulier.
Lorsqu'une exception non gérée se produit dans une tâche exécutée via un Task, le programme ne se termine pas, contrairement à l'usage direct du pool de threads. Pourquoi ?
Avec un Task, il est possible d'interagir avec la tâche. Il est possible d'attendre la fin de son exécution, et de récupérer son résultat si elle en renvoie un. Le fait qu'il soit possible d'interagir avec la tâche change tout. Il est en effet possible de récupérer l'exception et de la traiter.
Aussi, lorsqu'une exception survient dans un Task, elle est « mise en attente » jusqu'à ce qu'une interaction se produise (task.Wait, ou l'accès à task.Result par exemple). Lorsque l'interaction intervient, alors l'exception est propagée à la tâche effectuant cette interaction.
Cette propagation se fait en encapsulant l'exception initiale dans une exception de type AggregateException. Cette exception dispose d'une propriété InnerExceptions (notez le pluriel), qui permet d'accéder aux informations liées à l'exception.
La raison de l'encapsulation des exceptions tient dans la possibilité d'attendre plusieurs tâches (cf. Task.WaitAll. Le sujet sera abordé dans le second article de la série sur le pool de threads). Potentiellement, chacune des tâches peut générer une exception, et il faut donc pouvoir les traiter toutes. Aussi, une fois que toutes les tâches seront terminées (normalement ou non), alors toutes les exceptions qui se seront produites seront accessibles via cette AggregateException (d'où son nom) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
using System;
using System.Linq;
using System.Threading.Tasks;
namespace TaskWithException
{
class Program
{
static void Main(string[] args)
{
Task<string> task = Task.Run(new Func<string>(HelloWorld));
Console.WriteLine("Statut du task : {0}", task.Status);
Console.WriteLine("Fin du main");
Console.WriteLine("Statut du task : {0}", task.Status);
try
{
Console.WriteLine(task.Result);
}
catch(AggregateException ex)
{
Console.WriteLine("EXCEPTION : " + ex.InnerExceptions.First().Message);
}
Console.ReadLine();
}
private static string HelloWorld()
{
throw new NotImplementedException("TO DO");
}
}
}
Si jamais une tâche est lancée, mais qu'il n'y a pas d'interaction ensuite (on supprime l'accès à task.Result dans l'exemple précédent), alors l'exception est tout simplement ignorée ! Et il sera impossible d'y avoir accès ultérieurement.
C'est un effet de bord désagréable, car trouver alors la source de l'erreur nécessite une recherche approfondie.
VI. Conclusion▲
C'est un sujet tellement vaste. Il reste encore tellement de points à aborder, comme les fabriques de tâches, les jetons d'annulations ou encore du chaînage de tâches, le lien avec async/await.
Ces notions feront l'objet d'autres tutoriels à paraître, dont celui-ci sera le préambule.
Je remercie Siguillaume pour sa relecture technique et f-leb pour sa relecture orthographique.
VII. Code source▲
Le code source des différents exemples de ce tutoriel est disponible au téléchargement.
VIII. Références▲
Pool de threads : https://msdn.microsoft.com/fr-fr/library/0ka9477y(v=vs.110).aspx
Spécifications techniques :
classe ThreadPool : https://msdn.microsoft.com/fr-fr/library/system.threading.threadpool(v=vs.110).aspx
classe Task : https://msdn.microsoft.com/fr-fr/library/system.threading.tasks.task(v=vs.110).aspx